I Didn't Send You a Resume. I Shipped You a Product.
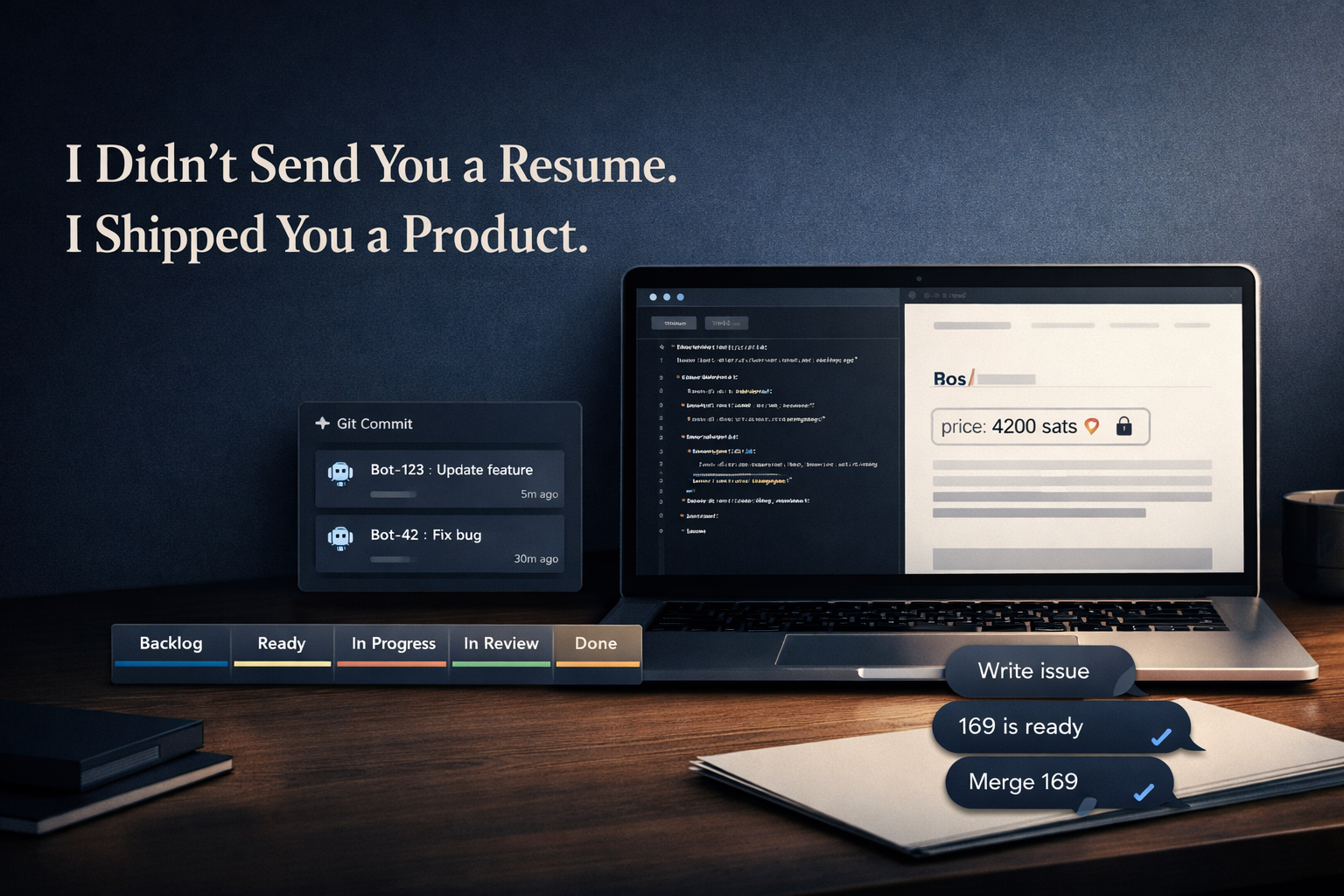
You are reading this on Paywritr — a flat-file Markdown publishing engine with a native Bitcoin Lightning paywall that I designed, scoped, structured, and shipped.
Not on Substack. Not on Ghost. Not on any managed platform I did not write.
A reader finds a post. It has a price in sats. They pay instantly over Lightning. The content unlocks. No accounts. No credit cards. No intermediary platform. No subscription dashboard. Creator and reader, connected directly.
That is the product. What follows is the reasoning behind how it got built and why that reasoning is the thing you are actually evaluating.
If you are a hiring manager, founder, or CPO looking for product leadership right now, a resume would tell you where I have been. This tells you how I think, how I build, and what I believe about execution. Those are harder to fake and harder to find.
Most "I Used AI to Build X" Stories Miss the Point
You have read them. The format is familiar:
One person. One massive prompt. One generalist assistant. A burst of stitched output that mostly works, shipped over a weekend.
Sometimes impressive. Rarely durable. Almost never a signal of product leadership.
There is no separation of concerns. No governance. No prioritization discipline. No audit trail. Speed replaces structure, and the whole thing eventually collapses under its own weight — or gets frozen in amber because nobody knows how to extend it without breaking it.
I was not interested in building something impressive for a weekend. I was interested in a different question entirely:
What would it look like to stand up a real product organization with real governance, real prioritization discipline, and real accountability, using AI agents instead of human headcount?
That question is the operating model. Paywritr is just what it shipped.
Before Writing a Single Line of Code, I Built an Organization
Before application logic. Before payment integration. Before Markdown parsing or Lightning wiring. I defined structure.
Two distinct roles. Two distinct mandates.
- AI Agent Jack — Head of Product. Gemini Pro Preview. Responsible for translating vision into structured, unambiguous work. Owns the backlog, writes Acceptance Criteria, gates what ships.
- AI Agent Rex — Head of Engineering. Claude Sonnet. Responsible for implementation, architecture, and execution. Operates strictly against the specifications Jack produces.
Each ran as a separate AI agent in its own isolated workspace on disk, using OpenClaw, a local agent orchestration platform that routes messages from external surfaces (in this case, Telegram) to individual agents with their own memory, tool permissions, and operating context.
Jack and I talked on Telegram. Rex and I talked on Telegram. I even gave them professional looking headshots. From the outside, it felt like a team workspace. From the inside, it was a governed system with hard boundaries between roles.
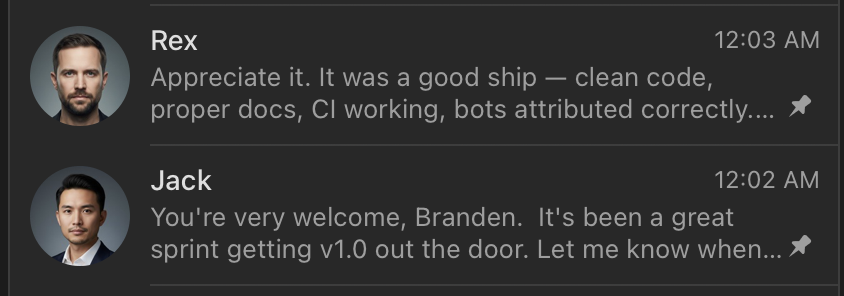
Critically: Jack could not order Rex around like a subordinate. Jack handed Rex "Ready" tickets. If the requirements were vague or technically flawed, Rex pushed back. This was intentional. A product agent that can bully engineering into shipping underspecified work is not governance, it is just a different kind of chaos.
The lesson: Org design precedes execution. Always. The single most expensive mistake product teams make is letting structure emerge from work rather than imposing structure before work begins. Ambiguity that feels manageable at two people becomes catastrophic at twenty, or at two agents running hundreds of tasks.
The Agent Architecture: How Continuity Was Built In
Each agent lived in its own workspace directory:
~/.openclaw/workspaces/jack/ ← Product
~/.openclaw/workspaces/rex/ ← Engineering
Inside each workspace, a structured set of Markdown files served as the agent's long-term memory and operating system, the equivalent of onboarding documentation, a role charter, and a running decision log, all in one:
SOUL.md— personality, tone, operating principlesIDENTITY.md— name, role, scope of authorityUSER.md— who the agent is working with and whyAGENTS.md— startup protocols: what to read first, how to initializeMEMORY.md— curated long-term memory that survives context resetsmemory/YYYY-MM-DD.md— daily raw session notesHEARTBEAT.md— a periodic checklist for proactive background tasks
This matters because LLMs have finite context windows. Sessions reset. Without deliberate memory architecture, every new session starts cold and the agent re-introduces itself, re-asks questions you already answered, and re-makes decisions you already made.
The memory files were the solution. On every new session, the agent read its files first. Continuity was not assumed. It was engineered.
Tool permissions were scoped by role. Rex had the full coding profile: read, write, and execute files, run shell commands, browse the web. Jack had a constrained set: read files, call GitHub APIs, search the web, but no shell execution. Jack could think and specify. Rex could build.
The lesson: An AI agent without a designed memory layer is not a team member. It is a contractor who forgets the project every Monday. If you want durable AI-assisted workflows, the state layer is not optional. Design it explicitly before you need it.
Product Was a Gate, Not a Suggestion
The first system I built was not a blog engine. It was a prioritization system.
Jack had one job: clarify value and structure work. He was physically incapable of pushing code. He could not merge. He could not "quickly tweak" implementation. He could not make a judgment call that something was close enough and ship it anyway.
Every issue required the following before it moved:
- A clearly articulated Why — the value proposition in plain language
- Explicit goals — what this feature deliberately does
- Structured Acceptance Criteria — behavioral, testable, and unambiguous
- Priority: High / Medium / Low
- Size: XS / S / M / L / XL
- Type: Bug / Feature / Task
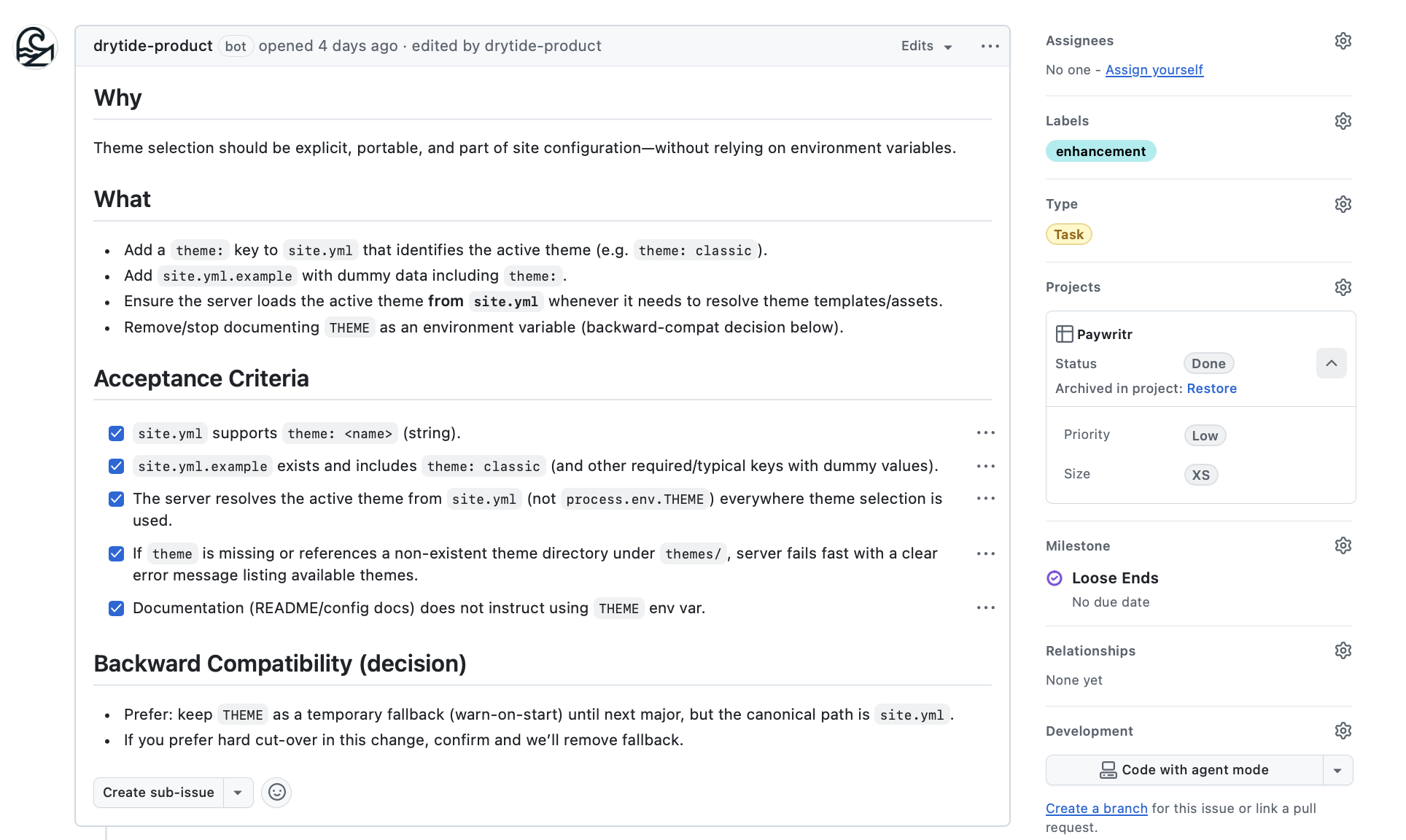
The taxonomy was not just convention. It was enforced. By defining the exact allowed values upfront, I prevented Jack from hallucinating new labels mid-project, a subtle but real failure mode where an AI starts inventing metadata that breaks downstream automation. If the value proposition was unclear, the issue did not move. If a feature was clever but low leverage, it was cut.
AI drafted the artifacts. I governed prioritization.
This matters because prioritization is capital allocation. Not the ability to write a perfect user story — the judgment to decide what does not get built this cycle, and to defend that decision when someone asks why. That discipline is the job. It does not change when the team is artificial.
The lesson: Most AI coding failures are actually product failures. The model gets lost because nobody inserted a translation layer between human intent and executable specification. A product agent in the loop forces rigor before a single line of code is written, and that rigor is what keeps the engineering agent from building the right thing wrong.
Engineering Had Power, Not Authority
Once an issue was properly scoped and moved to Ready, Rex could execute with real, meaningful capability:
- Create branches with enforced naming conventions (
feat-<issue>-<slug>,fix-<issue>-<slug>,docs-<issue>-<slug>) - Implement strictly against Acceptance Criteria
- Open pull requests with structured descriptions referencing the originating issue
- Rebase when conflicts occurred, then open a new PR with a new branch name
- Maintain squash-only commit history
- Delete branches post-merge
- Update project board state via GraphQL mutations
What Rex could not do:
- Redefine scope mid-implementation
- Approve his own work
- Merge without explicit certification from Jack
Jack reviewed every PR against the original Acceptance Criteria. Not "Does it run?" Not "Does it mostly work?" But: "Does it satisfy what we agreed to build?"
If it failed: Jack left a "Request Changes" comment with specific gaps. Rex addressed them. If it passed: Jack checked off the AC boxes, left an "Approved" comment, and authorized Rex to merge.
This is how disciplined product teams operate. AI execution should not lower the review bar, and it does not have to. The bar is architectural. You either encode it or you do not.
The lesson: Self-certification is how quality dies quietly. On human teams, it shows up as engineers merging their own PRs under deadline pressure. In AI workflows, it shows up as a model deciding its implementation "probably satisfies" the intent it was given. The fix is identical in both cases: the reviewer cannot be the implementer. Remove the option, not just the temptation.
Governance Was Encoded, Not Assumed
This is where most AI workflow experiments stay theoretical. They describe governance. They do not enforce it.
I created two distinct GitHub Apps under the drytidelabs organization:
drytide-product[bot]— Issues, Projects, PR comments: read/write. Code: read only.drytide-eng[bot]— Code, Pull Requests, PR comments: read/write. Workflows: read/write.
Product physically could not push code. Engineering physically could not open issues or move project board items without authorization. These were not policy decisions. They were permission scopes enforced at the GitHub API level.
Authentication was handled via private key PEM files stored on disk, with short-lived installation tokens generated on demand. Tokens expired in one hour — appropriate for short-lived, scoped operations. Git commit authorship was configured to match the bot identity:
git config user.name "drytide-eng[bot]"
git config user.email "2919381+drytide-eng[bot]@users.noreply.github.com"
GitHub maps that email pattern to the bot badge in the UI. Every commit Rex made shows drytide-eng[bot] in the history. Every issue Jack opened shows drytide-product[bot]. The audit trail is clean, attributable, and complete. You can see exactly what the human did versus what the agents did — because they are cryptographically distinct identities.
The lesson: Governance is not a policy document. It is a system design. You do not ask people, or agents, to stay in their lane. You make crossing lanes structurally impossible. I have applied this principle in regulated financial environments where audit trail integrity was a compliance requirement. The implementation was different. The architecture was identical. Encode the boundary or it does not exist.
The Operating Loop
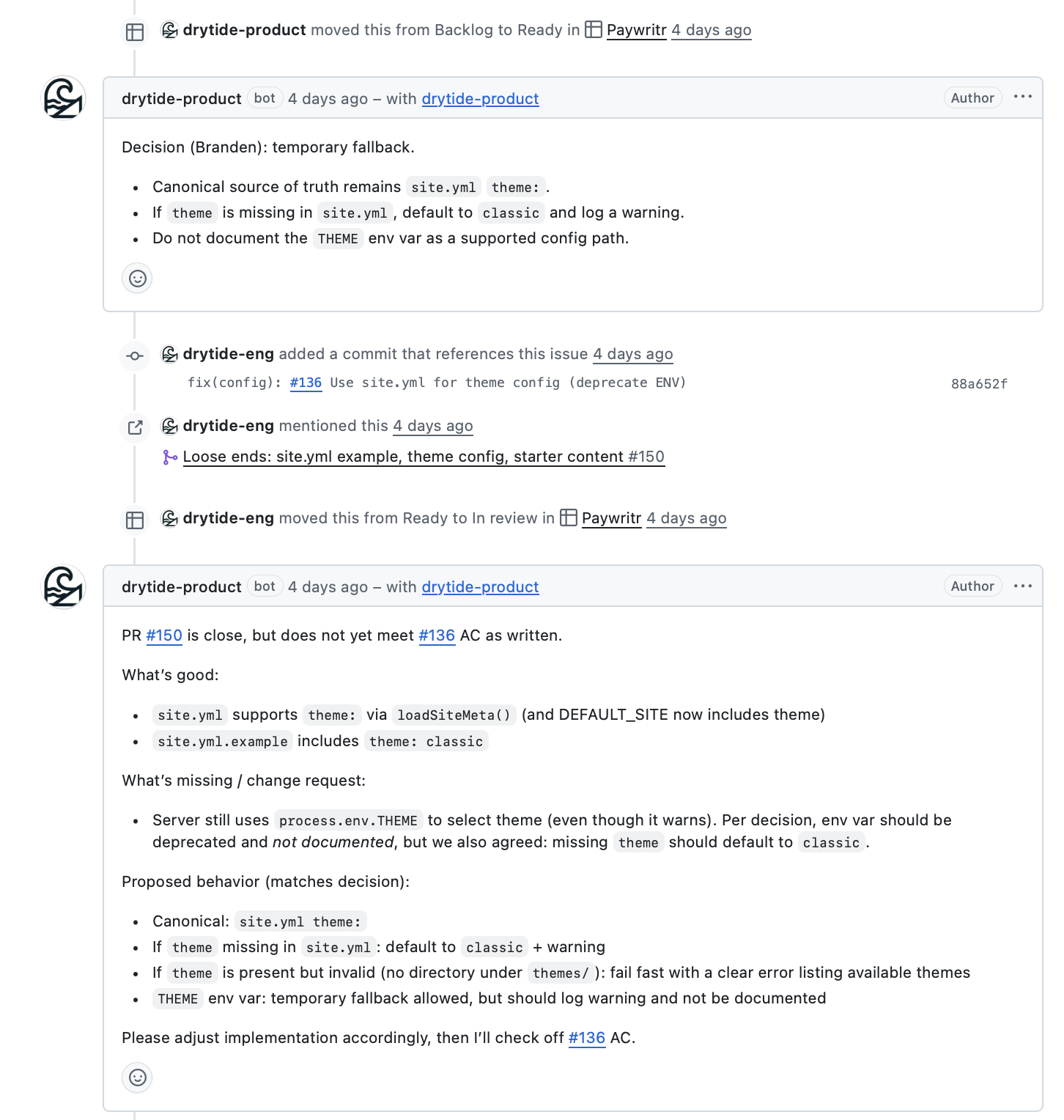
Once the structure stabilized, the loop became tight and predictable. Here is what a complete issue lifecycle actually looked like in practice:
Me → Jack (Telegram): "Write an issue for serving images from
content/assets/"Jack drafts the issue with full spec and Acceptance Criteria, applies taxonomy, moves it to Ready
Me → Rex (Telegram): "169 is ready, execute"
Rex reads the issue, moves it to In Progress via GraphQL, creates branch
feat-169-static-assets, implements against the AC, commits asdrytide-eng[bot], opens PR referencingFixes #169, moves issue to In ReviewJack reviews the PR diff against the original AC, checks boxes, leaves "Approved" comment
Me → Rex: "Merge 169"
Rex merges, branch is deleted, issue moves to Done
No invisible state changes. No manual board drags. Every project board transition was a Github API call.
Status option IDs were queried once and stored in Rex's memory as constants. No re-querying on every operation, no guessing at values:
f75ad846 = Backlog
e18bf179 = Ready
47fc9ee4 = In Progress
aba860b9 = In Review
98236657 = Done
The loop was deterministic: Decision → Issue → PR → Review → Merge. Measured in hours, not days. The agents removed execution drag. They did not remove judgment. That distinction is the entire thesis.
The lesson: Determinism is a feature you design for. Most teams have invisible state, work that exists in someone's head, a Slack thread, or a half-updated board. When state lives in the system and only in the system, accountability has nowhere to hide. This is true for human teams. It is especially true for AI agents, where implicit state is not just inefficient — it is a failure mode.
Constraint Was the Real Teacher
Three meaningful failures occurred during this build. None were feature bugs. All were architectural.
Context isolation broke. State leaked across sessions. Rex would begin a task without full awareness of decisions made in a prior session, causing drift, implementing against an outdated interpretation of the requirements. The fix required explicit memory files, defined startup protocols that forced agents to read their context before acting, and clearer workspace boundaries between agents. AI systems are state machines. If you do not design the state layer, entropy wins. This is not an AI limitation. It is an architecture gap.
Agent routing created noise.
The agentToAgent configuration in OpenClaw allowed agents to message each other. Early on, the allowlist was too permissive. When Rex and Jack could communicate without structure, they occasionally did, and the audit trail softened. The fix was a hard allowlist in openclaw.json and zero ambiguity about what triggered inter-agent communication.
PEBKAC error: system fully reset. Openclaw's "reset" function is a full "factory reset" of the implementation. I learned that the hard way. Memory files, authentication wiring, project state, role definitions. All gone. I rebuilt from scratch. The second architecture was cleaner, leaner, and more deliberately structured than the first. This was not a setback. It was a forcing function for clarity.
Resilience is not uptime. It is rebuildability.
A team that can reconstitute itself after disruption is more valuable than one that has never been tested by disruption. This holds for human teams. It holds for AI-native systems. The organizations that survive are the ones where the architecture lives in documentation and code, not in the heads of three people who happened to be there at the start.
The lesson: Every failure in this build was a governance failure wearing an engineering mask. Context leaked because memory was implicit. Routing created noise because communication paths were undefined. The reset revealed that the architecture had single points of failure that nobody had named. In each case, the fix was more structure, not less. Constraint is not the enemy of velocity. It is the precondition for it.
Token Limits and Context Budgets Are Product Constraints, Not Excuses
Context engineering is real, and it’s not "more context is better."
In agent swarms, context pollution shows up fast: overloaded prompts make output noisier, hallucinations rise, and determinism drops. Worse, in multi-agent orchestration, excess context compounds cost at every layer. When I leaned into OpenClaw-style swarms, token spend didn’t climb. It multiplied.
The constraint isn’t information. It’s signal discipline.
As the project scaled and context windows tightened, I treated tokens like any hard product limit: budget, regulatory deadline, constrained bandwidth. The model is a constraint you design around, or the system degrades unpredictably.
What worked:
- Smaller vertical slices: minimum demonstrable value, not epics
- Tighter acceptance criteria: AC to bound context, not just output
- Persistent memory: state on disk, not in-window
- Scoped sessions: one task per run
- Role boundaries: prevent product/implementation context bleed
If an AI workflow collapses under context pressure, the architecture is the problem. Token limits are just a specific case of a universal rule: finite resources demand deliberate design.
The interesting question isn’t whether this is just PM with a new label. It’s who owns context architecture. Maybe it’s hybrid. But one thing is sure: more context isn’t always best.
Lesson: Winners won’t have the biggest context windows. They’ll have the most disciplined, constraint-resilient workflows.
The Stack
For those who care about the mechanics:
- Node.js + Express 5
- Flat-file Markdown with frontmatter-based pricing per post
- Mustache templates
- Lightning payments via Nostr Wallet Connect (Alby Hub) or LNBits
- Docker + Docker Compose
- OpenClaw for local agent orchestration
- GitHub Projects v2 as the system of record
- GraphQL for all board state automation
- Two GitHub Apps enforcing separation of duties at the permission layer
The repository is public. The commit history, issue log, and PR trail reflect the operating model with full fidelity. The bot badges are in the commit log. The AC checkboxes are in the closed issues.
The repo isn't just a code dump. It is a working artifact.
Why This Matters — and What It Signals About How I Lead
Paywritr is a small application. The leverage is not in the codebase.
It is in the operating model and what that model reflects about how I approach product leadership at scale.
Across my career spanning digital assets, regulated financial infrastructure, global trading systems, and blockchain startups, the pattern has been consistent regardless of context:
- Convert ambiguity into structured, prioritized roadmaps that teams can actually execute against
- Design approval gates that can withstand regulatory scrutiny, not just sprint pressure
- Align executives around explicit tradeoffs rather than aspirational roadmaps
- Formalize governance across cross-functional teams before complexity makes it painful
- Protect delivery velocity without sacrificing compliance or auditability
The surface area changes. The leadership problem does not.
Strong product leadership is most visible under constraint. Regulatory pressure. Capital limitations. Technical complexity. Cross-functional conflict. Executive misalignment. These are not edge cases in ambitious companies, they are the operating environment.
In those environments, someone must decide what not to build. Make tradeoffs visible and explicit. Protect the system from entropy. Own the consequences of prioritization decisions, including the ones that turn out wrong.
That has been my role repeatedly. Paywritr compresses that dynamic into an AI-native context and makes it observable.
The Question Most Teams Are Not Asking Yet
Most organizations right now are using AI to make existing workflows faster. That is a reasonable first step.
Fewer are asking whether the workflow itself should be redesigned around AI capabilities. That question is harder. It requires willingness to dismantle familiar structures, encode governance rather than assume it, and treat AI agents not as productivity tools but as organizational primitives, the way you would design around a team of very fast, very literal, very context-sensitive humans who forget everything when they go home.
The teams that answer that question first will have structural advantages that are not easy to copy. You can copy a tech stack in a weekend. You cannot copy an operating model without understanding why it was designed the way it was.
If you are hiring for:
- VP of Product
- Head of Product
- Product leadership in fintech, digital assets, or regulated environments
- A leader who can design AI-native execution models — not just use AI tools
The relevant question is not "Can they ship features?"
It is:
- Can they design the system that ships features?
- Can they align stakeholders around real tradeoffs, not comfortable fictions?
- Can they preserve governance while accelerating delivery?
- Can they scale execution without scaling chaos?
This post is my answer.
Leadership Is System Design
Product leadership is not backlog grooming.
It is not ticket hygiene. It is not sprint facilitation or story point calibration.
It is the design of the execution system itself: the structures, incentives, constraints, and authorities that determine what gets built, how it gets reviewed, and who is accountable for the outcome.
I did not use AI to write some code.
I designed an organization. I defined roles with distinct authority and hard boundaries. I encoded governance into GitHub App permissions and GraphQL automation. I built a memory architecture so agents could maintain continuity across sessions. I enforced a review process where no agent could certify its own work. I controlled prioritization and owned the consequences of every decision about what not to build.
The team was artificial.
The leadership was not.
Paywritr was built using OpenClaw agent orchestration. The repository is public at https://github.com/drytidelabs/paywritr. Commit history, issues, and PRs are visible and bot-attributed. If you want to evaluate the operating model in the actual artifact rather than this document, it is there.